Hi 👋, In this blog post, I’ll be exploring a relatively new artifact in Windows 11. This artifact is related to the Notepad application and contains information from saved or unsaved data in the Windows Notepad application. I’ve been working on this artifact on and off since the beginning of the year, I’ve been busy with not working 😃.

In this post, I’ll try something new: I’ll walk you through my thought process during the analysis of this artifact, including how I identified certain fields by examining the binary data and by reversing the Notepad binary.
So, let’s get started!
Note that this research was done on Windows 11, 23H2 - 226313737 and Notepad v11.2406.9.0 (for up-to-date changes to notepad structure, refer to New Changes below)
The Notepad artifacts are located at the path %LOCALAPPDATA%\Packages\Microsoft.WindowsNotepad _8wekyb3d8bbwe\LocalState, this directory contains two folders:
| Folder Name | Details |
|---|---|
| TabState | This folder contains files for each tab in Notepad. These files contain the most interesting data |
| WindowsState | This folder contains information about the Notepad windows (e.g., the currently focused tab, etc.). |
In this post we will only focus on the TabState as it has most of the interesting data for Digital Forensics.
TabState ⏳
This folder contains files with the format <GUID>.bin, from what I can see, the GUID is auto generated and it isn’t driven from the data. You will also see files that has the format <GUID>.0.bin and <GUID>.1.bin, these files are a temporary files where the data will be written to before it will be written to the main file (i.e <GUID>.bin) and they don’t contain much data. Here is an example of the generated data:
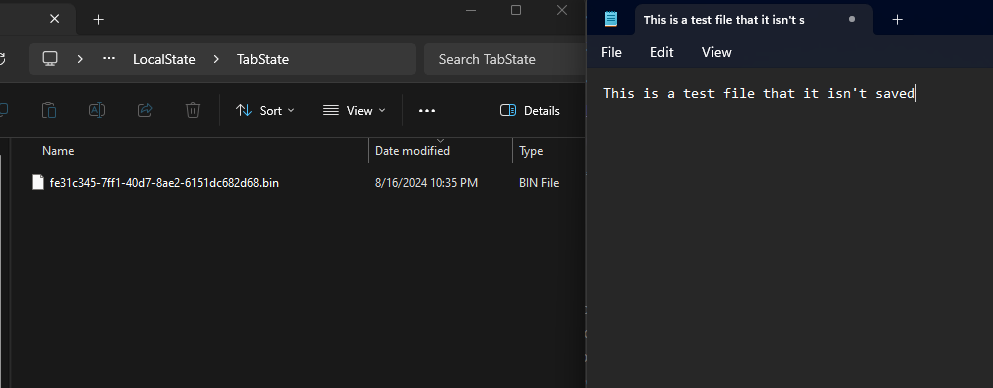
The content of the file looks like this for unsaved files:
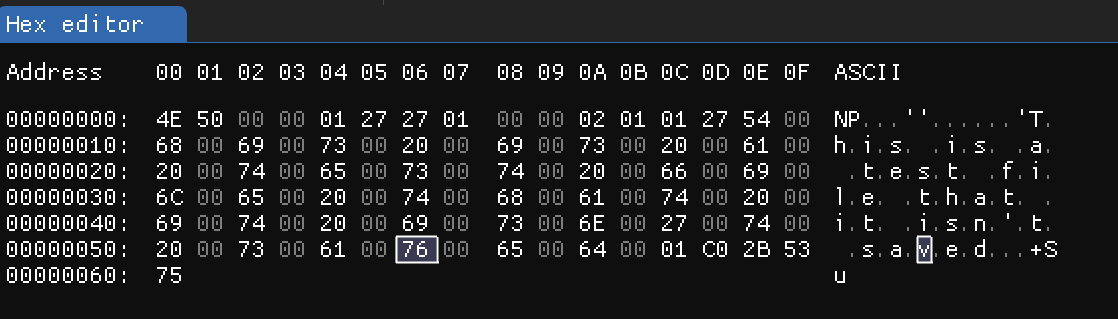
For the TabState data for saved files, I did the following as an example for this post:
- Opened a new tab
- Wrote the text
This is a test file saved - Saved the file to
C:\Windows\Temp\u0041.txt
TabState data was generated with the name 79f851b1-e2d3-45ad-82d4-b69c87c40eeb.bin and it looks like this:
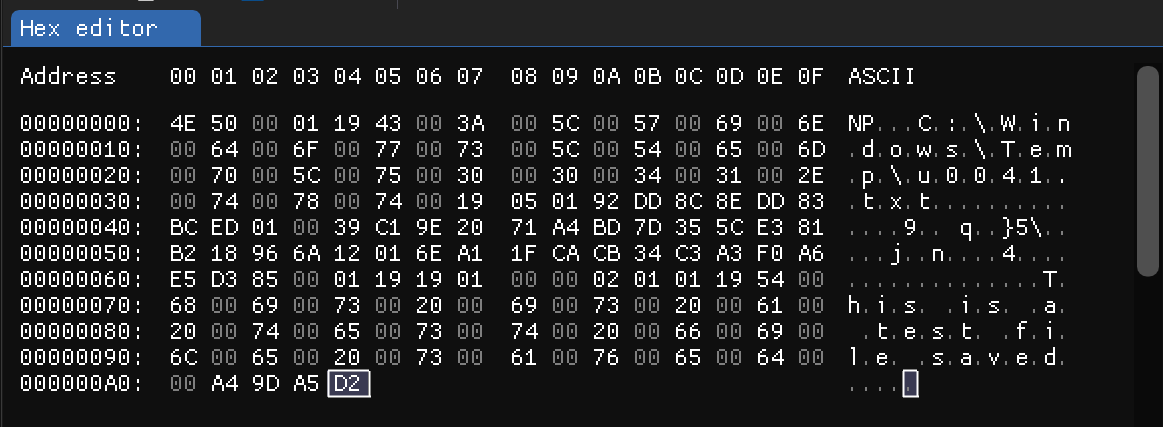
From this point forward, we will focus on the structure of the TabState data for saved files, as they are more inclusive. This means that saved files contain more data, whereas unsaved files have less data, as you might expect. So, let’s start examining the data and see what we can discover before beginning the reverse engineering of Notepad executable.
Structure Analysis 🧩
To identify the structure of any artifact, I usually follow two approaches:
- Poking at it: This involves opening the file in a hex editor to see what I can observe. It helps me get familiar with the artifact.
- Reversing: Using debuggers and disassemblers to investigate what data is written to the artifact file and when.
Lets get started!
Poking at it 👉
From the image above for the TabState data, we can see some data we can identify. Here it what we can see:
- Full path for the
TXTfile at offset0x05 - Content of the file at the offset
0x6E
Notice that both of these strings are encoded in UTF-16LE and they don’t end with a null byte (i.e 00 00). That means we must have a string length of these strings some where in the data. Usually, it is before the string itself. The size could be in bytes length or character length, in UTF-16LE encoding, characters are encoded into two bytes. Here is the lengths of these strings:
- Path length at offset
0x04(25) - Content length at offset
0x6d(25)
The string C:\Windows\Temp\u0041.txt is 25 characters in length, so we know we are correct on our assumption. Also, the content length is 25 characters which is also reported correctly.
But, did you noticed something weird? why the length is only one byte? What if the content is more than 255 characters? As we will see later on this post, this is not a single byte (will, kind of…).
If you noticed in the data for saved and unsaved files, there is one byte at the offset 0x03 which is set to 00 or 01, What is that? will it turns out it will be set to 00 if the file is not saved to a path or to 01 if the file is saved to a path.
From my testing, I noticed that the last four bytes always appear random. I suspected they might be some kind of checksum, most likely a CRC32 checksum given the number of bytes. To verify this, I used the Hashes feature in my hex editor (IamHex) and selected all bytes except the last four. Then, I kept offsetting my selection by one byte until I got the correct hash!
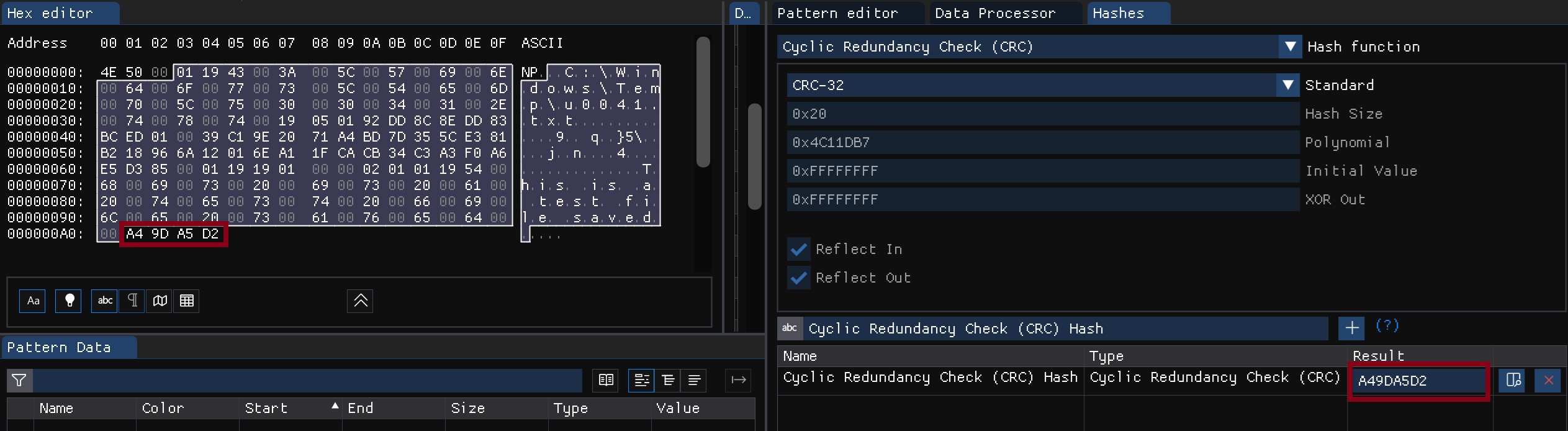
So, it is CRC32 hash for the TabState content starting from the offset 0x03 and excluding the last four bytes.
There is one byte at the offset 0xA0 which acts as a flag if the file contain unsaved data. This will always be 01 for unsaved TabState files and either 01 or 00 if the content is saved or not in the TabState files related to saved files.
Great! so far we have the following:
- Is file saved flag
- Path length
- Full path
- File content length
- File content
- Contain unsaved data flag
- CRC32 hash for the content starting from offset
0x03and excluding the last four bytes
Ok, we got some data from TabState, but there is more data to be parsed. Time to start reversing Notepad and look for the code responsible of writing these TabState files.
Reversing 🔬
For this stage, I use a combination of tools. The tools I use are listed below:
| Tool | Details |
|---|---|
| Ghidra | My tool of choice for reverse engineering is a very good option, especially since it is FOSS (Free and Open Source Software). |
| Api Monitor | I usually use this tool to get a quick overview of functions of interest. |
| x64dbg | My debugger of choice |
So, let’s start with Api Monitor to identify interesting functions. Looking through it, I saw some interesting functions which are BCryptOpenAlgorithmProvider and BCryptHashData :
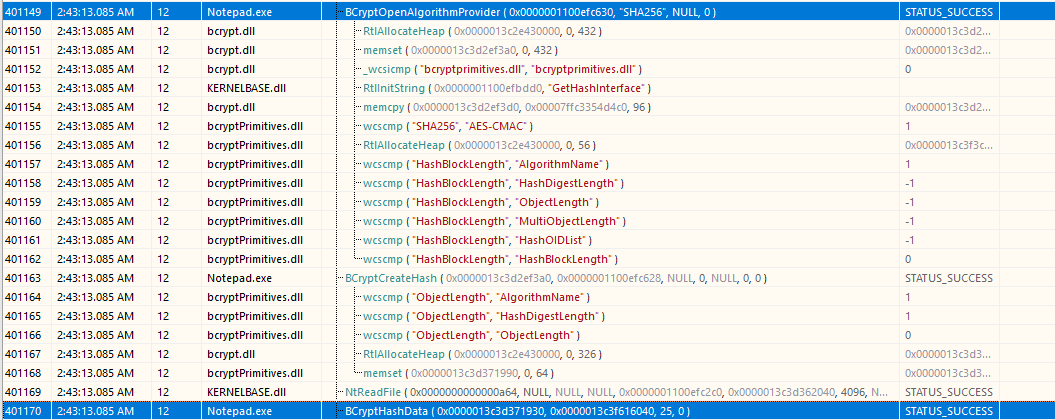
From the image above, you can see that the string SHA256 is passed to the function BCryptOpenAlgorithmProvider as the argument pszAlgId. According to the Microsoft documentation, this function creates a crypto handle for the specified algorithm (i.e., SHA256). On the other hand, BCryptHashData accepts the data to be hashed. So, what is the data that will be hashed? Will it be the content of the file, as we can see below:

Now, let’s ensure that the file hash matches what is shown in the TabState data. We can do this by calculating the SHA256 hash of the file and checking if it matches the data in the TabState:
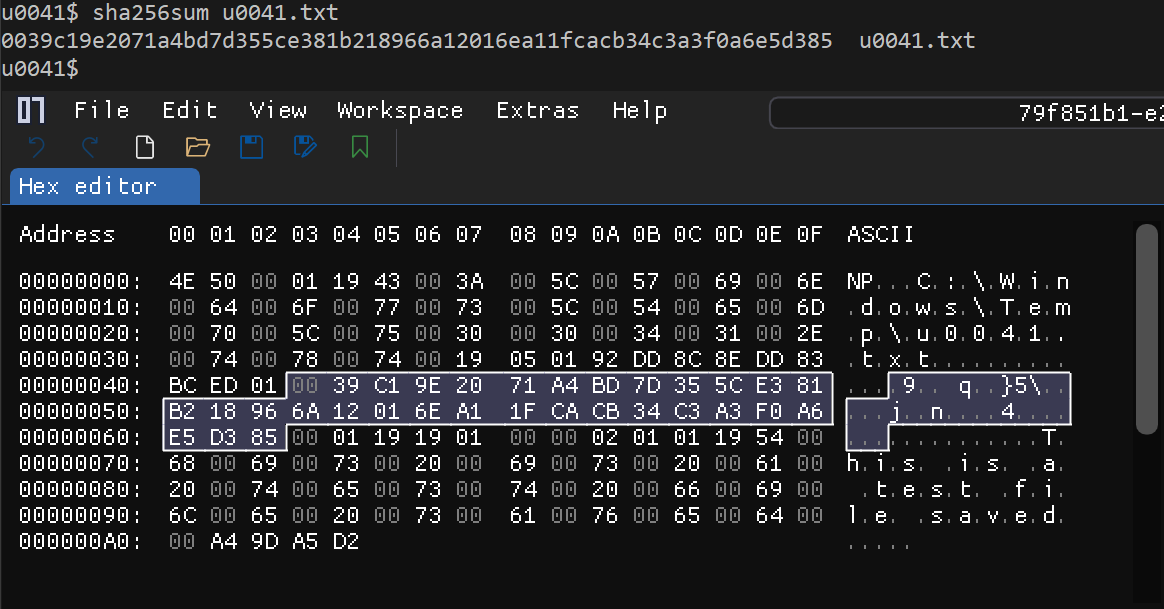
Great, the hashes match!

Let’s start Ghidra up and take a look. So, where do we start? Will the TabState file need to be written to the file system at some point. So, lets see which functions calls the WriteFile API. I found a function which looks like the main function responsible of creating, building and writing the TabState files. Going through the code looking for any additional data which is written to the TabState, I found a function called FUN_140017ca0 that accepts a string as the first argument:
// <TRANCATED>
LAB_140008a89:
FUN_140017ca0("file_size",iVar3,(undefined8 *)local_1c8);
pcVar2 = (code *)swi(3);
(*pcVar2)();
return;
}
FUN_140005000((void **)local_1c8);
if (local_178 == *(ulonglong *)(param_1 + 0x20)) {
do {
pvVar7 = (void *)((longlong)pvVar7 + 1);
} while (*(short *)((longlong)puVar6 + (longlong)pvVar7 * 2) != 0);
local_1c8 = ZEXT816(0);
local_1b8 = 0;
local_1b0 = 0;
FUN_140004f40((void **)local_1c8,puVar6,pvVar7);
pWVar5 = (LPCWSTR)local_1c8;
if (7 < local_1b0) {
pWVar5 = (LPCWSTR)local_1c8._0_8_;
}
iVar3 = FUN_1400a4268(pWVar5,&local_180,0x21,0xffffffff);
if (iVar3 != 0) {
iVar3 = FUN_140017ca0("last_write_time",iVar3,(undefined8 *)local_1c8);
goto LAB_140008a89;
}
// <TRANCATED>
So, does it record the last write time of the file and file size? This part took me some time to figure out 😅. Usually, windows will record timestamps in FILETIME structure which is basically a u64 for the number of 100 nanosecond since 1601-01-01 in UTC. So, I looked all over the structure in the hex editor looking for FILETIME, Unfortunately, I didn’t find anything. So where is it?

One night while I was looking at the unknown data, shown in the image below (green is known):
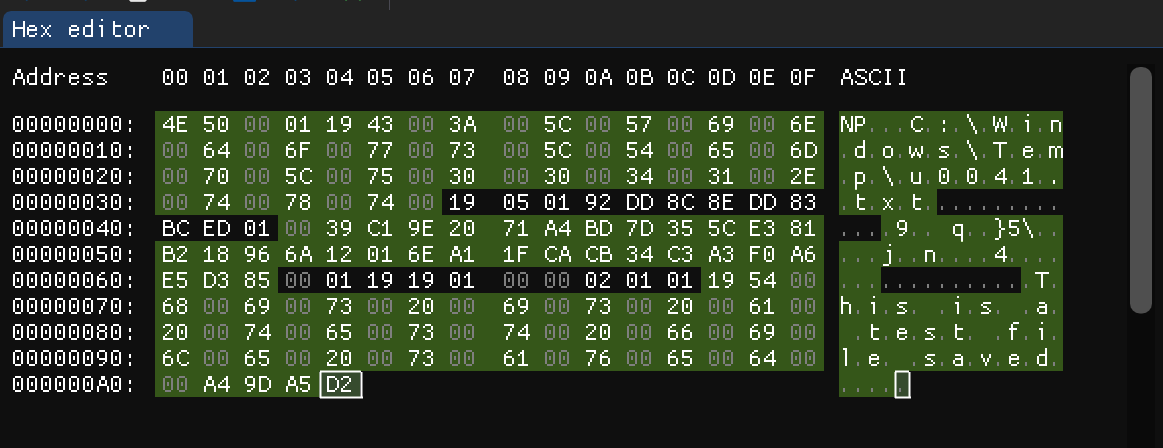
We know that FILETIME is at lest u64 which means it is 8 bytes, So, I kept selecting 8 unknown bytes at a time and looking to the Data Inspector in my hex editor. And I found it!
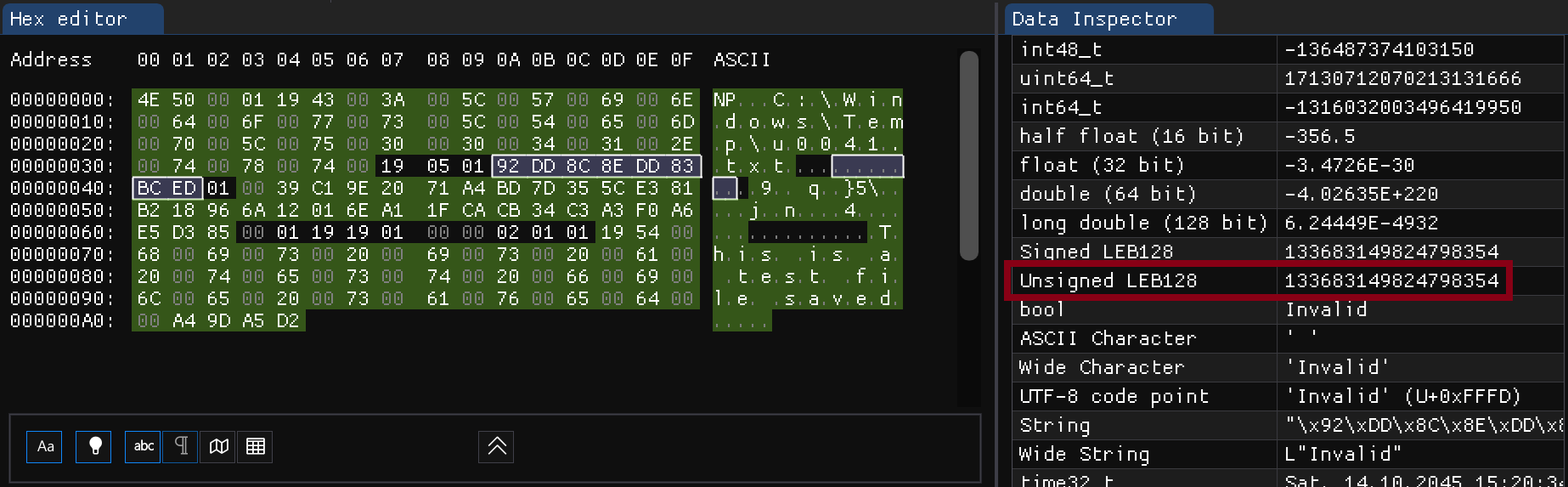
So, what is Unsigned LEB128 or uLEB128? Well, LEB128 is a method for storing integers using as few bytes as possible. You can think of it as a compression method for integers.
Remember that we said it is weird where sizes are in a single byte (ex. file content size)? Well, it wasn’t a single byte, it is uLEB128 encoded. I get why windows will use it for sizes, but why would they use it for FILETIME? I have no idea 😃
Ok, What about the size? we can see at the offset 0x37 is 25 which is file size in uLEB128.
Here is the known data so far, highlighted in green:
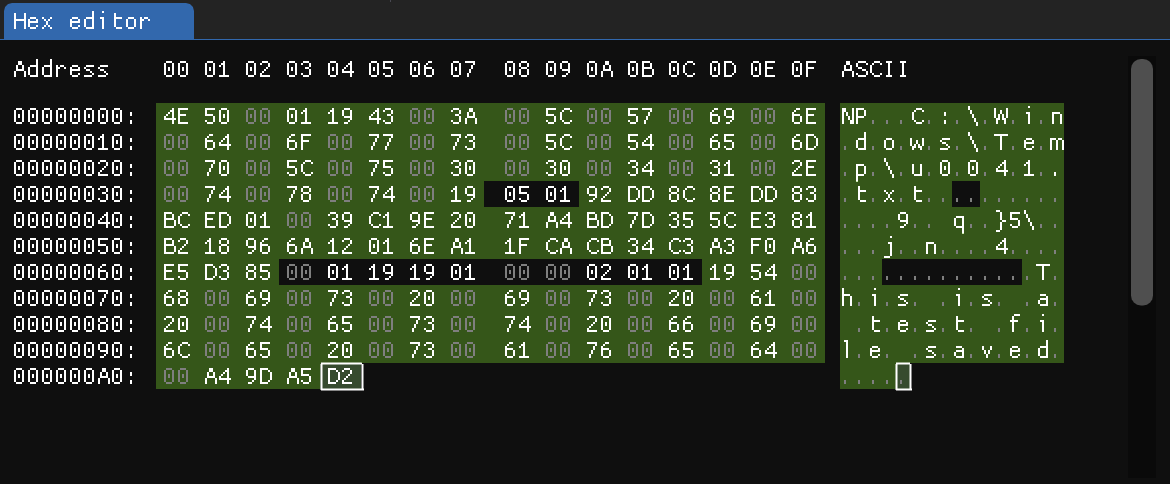
I was able to identify all of the data mentioned above earlier this year. At that time, there weren’t many people discussing this artifact. However, after revisiting the artifact a couple of weeks ago, I found that there has been excellent research conducted on it. This includes not only the TabState but also the WindowState. I highly recommend reading about it here. Below is the unknown data from the picture above, as detailed in the research:
- Text encoding type at
0x38 - Carriage return type at
0x39 - Two unknown bytes at
0x63 - Cursor selection start at
0x65inuLEB128 - Cursor selection end at
0x66inuLEB128 - Configuration block
- Word wrap flag
- RTL flag
- Show Unicode flag
- Version & more options in
uLEB128 - Optional two bytes depending on the field
Version & more options
In addition to the data mentioned above, TabState might contain a list of structures. Each structure represents data that has not been saved. From now on, we will refer to this structure as UnsavedChunk. Here are the fields represented in this struct:
- Cursor position in
uLEB128, this is where the data will be inserted or deleted - Number of deletion in
uLEB128, this is the number of characters to delete - Number of addition in
uLEB128, this is the number of characters to add - Characters in
UTF-16LE, in case theNumber of additionis more than0, this will be the characters to add - CRC32 Checksum for the previous bytes
This structure isn’t shown in our example.
Finally, we have a very good understanding about the structure for this artifact. Here is how it looks like after parsing the data:
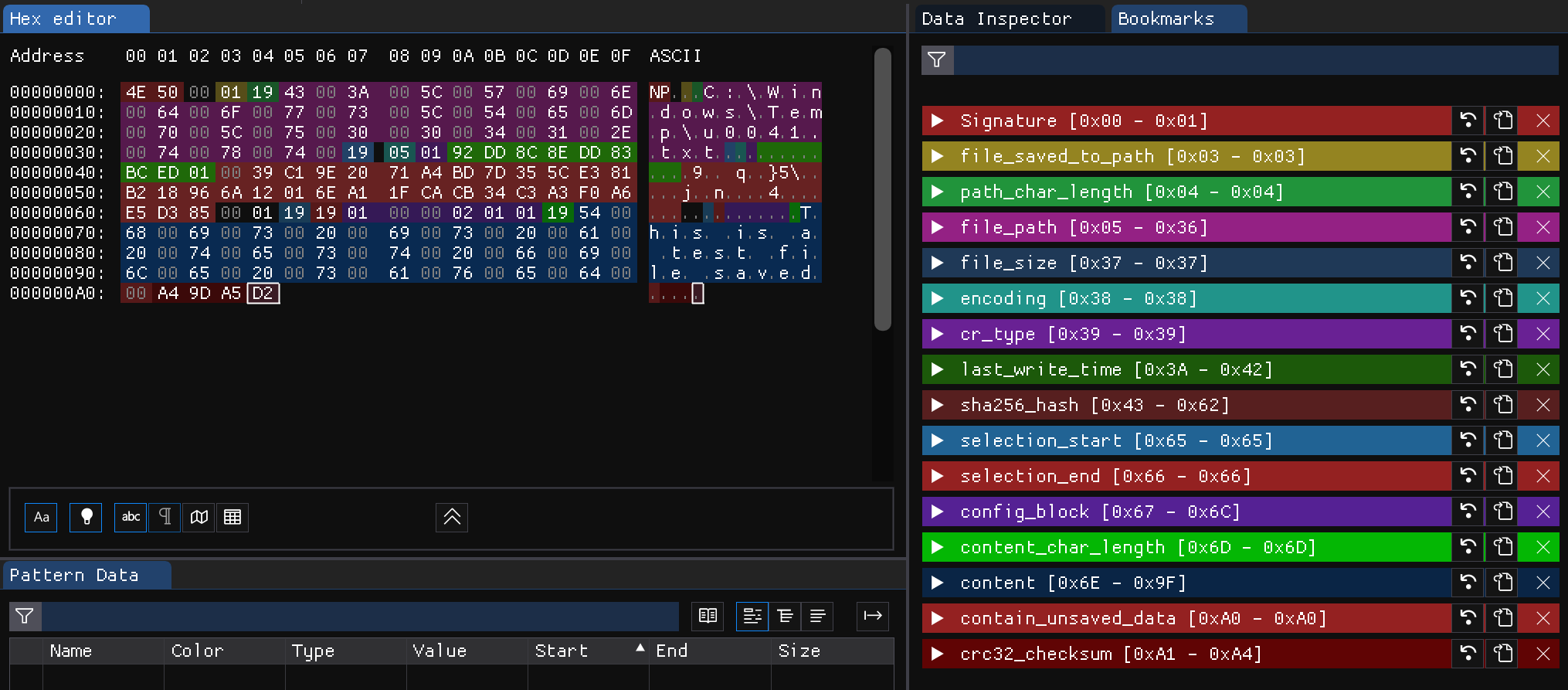
Final Structure 📐
The structure for TabState differs if the data is for files saved to path or not. I am going to separate them into two tables:
Structure for Saved Tabs - TabState 💾
| Field | Type | Details |
|---|---|---|
| signature | [u8;2] | This is always NP |
| unknown0 | u8 | This is always 00, might be a null terminator for the signature |
| file_saved_to_path | bool | If 00 the file isn’t save to a path, 01 otherwise |
| path_length | uLEB128 | The length of the file path in characters |
| file_path | UTF-16LE | The full path to file on disk |
| file_size | uLEB128 | The file size on desk |
| encoding | u8 | The file encoding:0x01 for ANSI0x02 for UTF-16LE0x03 for UTF-16BE0x04 for UTF-8BOM0x05 for UTF-8 |
| cr_type | u8 | Carriage return type:0x01 for CRLF0x02 for CR0x03 for LF |
| last_write_time | uLEB128 | The last write time of the original file as FILETIME |
| sha256_hash | [u8;32] | The SHA256 hash for the original file |
| unknown1 | [u8;2] | Unknown bytes, always 00 01 |
| selection_start | uLEB128 | The position of selection start |
| selection_end | uLEB128 | The position of selection end |
| config_block | ConfigBlock | A configuration stored in ConfigBlock structure |
| content_length | uLEB128 | The length of the content in characters |
| content | UTF-16LE | Content on the TabState file |
| contain_unsaved_data | bool | If 00 then content in TabState is the same on the original file, 01 otherwise. This is always 01 for TabState files without corresponding file on disk (unsaved tab) |
| checksum | [u8;4] | CRC32 checksum for the above data starting from offset 0x03 |
| unsaved_chunks | [UnsavedChunck] | A list of the structure UnsavedChunck |
Structure for Unsaved Tabs - TabState 🚫
| Field | Type | Details |
|---|---|---|
| signature | [u8;2] | This is always NP |
| unknown0 | u8 | This is always 00, might be a null terminator for the signature |
| file_saved_to_path | bool | Always 00 |
| unknown1 | u8 | This is always 01 |
| selection_start | uLEB128 | The position of selection start |
| selection_end | uLEB128 | The position of selection end |
| config_block | ConfigBlock | A configuration stored in ConfigBlock structure |
| content_length | uLEB128 | The length of the content in characters |
| content | UTF-16LE | Content on the TabState file |
| contain_unsaved_data | bool | Always 01 |
| checksum | [u8;4] | CRC32 checksum for the above data starting from offset 0x03 |
| unsaved_chunks | [UnsavedChunck] | A list of the structure UnsavedChunck |
Structure for ConfigBlock ⚙️ - EDITED
| Field | Type | Details |
|---|---|---|
| word_wrap | bool | if 01 then word wrap is set, 00 otherwise |
| rtl | bool | if 01 then right to left is set, 00 otherwise |
| show_unicode | bool | if 01 then show unicode control characters is set, 00 otherwise |
| version | uLEB128 | Version number of the structure |
| unknown0 | Option<[u8;2]> | Optional values depending on the value of version. Reserved? |
| formatting_type | Option<u8> | EDITED: the format of the content.1 for Unformated2 for Markdown3 for MarkdownSyntaxThis is only present if version is > 2 |
Structure for UnsavedChunk 🗃️
| Field | Type | Details |
|---|---|---|
| cursor_position | uLEB128 | The position where the data will added to or deleted from |
| deletion_number | uLEB128 | The number of characters that will be deleted from the position cursor_position |
| addition_number | uLEB128 | The number of characters that will be added to the position cursor_position |
| chars | Option<UTF-16LE> | In case addition_number is grater than 0, this will be the characters to be added |
| checksum | [u8;4] | CRC32 checksum for the previous bytes |
The Parser 🦀
I wrote a library and executable parser in Rust to parse TabState file and output them in multiple formats (jsonl and csv). Here is the help message for the tool:
Created By: AbdulRhman Alfaifi <aalfaifi@u0041.co>
Version: v0.1.0
Reference: https://u0041.co/posts/articals/exploring-windows-artifacts-notepad-files/
Notepad TabState file parser
Usage: notepad_parser.exe [OPTIONS] [FILE]
Arguments:
[FILE] Path the files to parse. Accepts glob. [default: C:\Users\*\AppData\Local\Packages\Microsoft.WindowsNotepad_8wekyb3d8bbwe\LocalState\TabState\????????-????-????-????-????????????.bin]
Options:
-f, --output-format <FORMAT> Specifiy the output format [default: jsonl] [possible values: jsonl, csv]
-o, --output-path <FILE> Specifiy the output file [default: stdout]
-l, --log-level <LEVEL> Level for logs [default: quiet] [possible values: trace, debug, info, error, quiet]
-h, --help Print help
-V, --version Print version
-V, --version Print version
The following is the output of the tool for the test file we used in this post:
{
"tabstate_path": "C:\\Users\\u0041\\AppData\\Local\\Packages\\Microsoft.WindowsNotepad_8wekyb3d8bbwe\\LocalState\\TabState\\79f851b1-e2d3-45ad-82d4-b69c87c40eeb.bin",
"seq_number": 0,
"is_saved_file": true,
"path_size": 25,
"path": "C:\\Windows\\Temp\\u0041.txt",
"file_size": 25,
"encoding": "UTF8",
"cr_type": "CRLF",
"last_write_time": "2024-08-16T20:49:42Z",
"file_hash": "0039C19E2071A4BD7D355CE381B218966A12016EA11FCACB34C3A3F0A6E5D385",
"cursor_start": 25,
"cursor_end": 25,
"config_block": {
"word_wrap": true,
"rtl": false,
"show_unicode": false,
"version": 2,
"unknown0": 1,
"unknown1": 1
},
"file_content_size": 25,
"file_content": "This is a test file saved",
"contain_unsaved_data": false,
"checksum": "A49DA5D2"
}
And here is an example for a test file that contains UnsavedChunk data:
{
"seq_number": 0,
"is_saved_file": true,
"path_size": 24,
"path": "C:\\Windows\\Temp\\test.txt",
"file_size": 32,
"encoding": "UTF8",
"cr_type": "CRLF",
"last_write_time": "2024-08-08T22:18:57Z",
"file_hash": "C60D8FFBD2FF969A36BFFCA31F609E801E8E0B8DE41568E948DBEBAC1BD9B2E4",
"cursor_start": 31,
"cursor_end": 31,
"config_block": {
"word_wrap": true,
"rtl": false,
"show_unicode": false,
"version": 2,
"unknown0": 1,
"unknown1": 1
},
"file_content_size": 31,
"file_content": "File saved test\rFile saved test",
"contain_unsaved_data": false,
"checksum": "F44C93E7",
"unsaved_chunks": [
{
"position": 31,
"num_of_deletion": 0,
"num_of_addition": 1,
"data": "\r",
"checksum": "90FEE334"
},
{
"position": 32,
"num_of_deletion": 0,
"num_of_addition": 1,
"data": "t",
"checksum": "4D720EDC"
},
{
"position": 33,
"num_of_deletion": 0,
"num_of_addition": 1,
"data": "h",
"checksum": "96657A31"
},
{
"position": 34,
"num_of_deletion": 0,
"num_of_addition": 1,
"data": "i",
"checksum": "C8DE31A0"
},
{
"position": 35,
"num_of_deletion": 0,
"num_of_addition": 1,
"data": "s",
"checksum": "4593E2CB"
},
{
"position": 36,
"num_of_deletion": 0,
"num_of_addition": 1,
"data": " ",
"checksum": "6625304C"
},
{
"position": 37,
"num_of_deletion": 0,
"num_of_addition": 1,
"data": "a",
"checksum": "B22767B8"
},
{
"position": 38,
"num_of_deletion": 0,
"num_of_addition": 1,
"data": " ",
"checksum": "1CE5632C"
},
{
"position": 38,
"num_of_deletion": 1,
"num_of_addition": 0,
"checksum": "DA9AD201"
},
{
"position": 37,
"num_of_deletion": 1,
"num_of_addition": 0,
"checksum": "D8DC6C58"
},
{
"position": 37,
"num_of_deletion": 0,
"num_of_addition": 1,
"data": "i",
"checksum": "7AFEEDB0"
},
{
"position": 38,
"num_of_deletion": 0,
"num_of_addition": 1,
"data": "s",
"checksum": "8D736DBB"
},
{
"position": 39,
"num_of_deletion": 0,
"num_of_addition": 1,
"data": " ",
"checksum": "21854A9C"
},
{
"position": 40,
"num_of_deletion": 0,
"num_of_addition": 1,
"data": "u",
"checksum": "6419745C"
},
{
"position": 41,
"num_of_deletion": 0,
"num_of_addition": 1,
"data": "n",
"checksum": "F04F9676"
},
{
"position": 42,
"num_of_deletion": 0,
"num_of_addition": 1,
"data": "s",
"checksum": "488380BA"
},
{
"position": 43,
"num_of_deletion": 0,
"num_of_addition": 1,
"data": "a",
"checksum": "0D17D9D9"
},
{
"position": 44,
"num_of_deletion": 0,
"num_of_addition": 1,
"data": "v",
"checksum": "BAB4815F"
},
{
"position": 45,
"num_of_deletion": 0,
"num_of_addition": 1,
"data": "e",
"checksum": "E63BE97D"
},
{
"position": 46,
"num_of_deletion": 0,
"num_of_addition": 1,
"data": "d",
"checksum": "B880A2EC"
}
],
"unsaved_chunks_str": "[31]:\rthis a <DEL:38><DEL:37>is unsaved"
}
In the example above, you can see the raw list of UnsavedChunk structures in the field unsaved_chunks, as well as a field called unsaved_chunks_str, which contains a normalized version of the data.
You can download the parser from here: https://github.com/AbdulRhmanAlfaifi/notepad_parser
Final Notes 📝
Here are some observations I made during the analysis:
- All strings are saved in
UTF-16LE, regardless of the original encoding. Theencodingfield is most likely used only for decoding the data within the Notepad application. - Regarding operations in the
UnsavedChunk, you will notice that it adds one character at a time. However, if the user pastes text, the entire text will be added to a single chunk. Think of this as when youCTRL+ZinNotepadit will remove the most resent chunk. TabStatefiles don’t have a limit on content size. I tested aTXTfile larger than500 MB, and it still contained the full content of the original file in theTabState. This is very useful for digital forensics!
New Changes 🔄
In this section I will add the changes observed in new version:
Notepad Version 11.2508.38.0
- Added formatting to text files, the format type is in the
ConfigBlockstructure namedformatting_type. The following are the possible formatting types:- unformated (plain text)
- Markdown (show up formatted in notepad)
- MarkdownSyntax (show raw markdown syntax)
- Saved files no longer contain the file content in the field
file_content - Saved files no longer record the last modification time in the field
last_write_time. Instead this field will be0 - The file hash is no longer recorded in the field
file_hash - The
versionfield is now set to3